

文字化けの調査方法
- DPZで2020年2月に公開された全記事(ただし、べつやくさんなどの画像ベースの記事は除く)を取得し、全記事をひとつのテキストファイルにまとめ、保存する。
- サクラエディタを使って、様々な文字化けを発生させ、保存する
- 各文字の出現回数をカウントするプログラムを作り、プログラムを実行し、文字化けランキングを作成する。

インターネットといえば、文字化け。最近はあまり見ることがなくなったが、それでもたまに遭遇する文字化け。我々は文字化けを嫌いすぎている。もっと、文字化けを愛すべきではないか?
インターネットが普及して20年をゆうに超える。メール、添付ファイル、Webブラウザなど、様々な場面で我々は文字化けに苦しめられてきたし、今でもたまに苦しめられる。「文字が化ける」と書いて文字化け。そこにはお化けみたいで悪いイメージがあるが、それも仕方がない。読めないのだから。必要な情報が読めないのはシンプルに悪いことだ。

でも、一方的に文字化けを避けていては、文字化けと仲良くなれない。文字が化けた先にあるのは文字だ。化ける前の文字ばかり愛していては、化けた後の文字がかわいそうではないか。我々は、化けた後の文字をもっと愛すべきなのだ。
文字化けでよく見る文字ってなんだろう。そんな疑問から、まずは「文字化けランキング」を作ってみた。調査方法はこうだ。




文字化けのランキングができた。結果はこんな感じ。(UTF8とかSJISとかについては後でくわしく説明します。)

DPZの2月の記事をすべてUTF8→SJISで文字化けさせると、「縺」は101982回も出現する。多いな・・・。
せっかくなので、文字化け無しの状態で、文字の出現回数カウントプログラムを実行してみた。

ランキングに従い、さっそく文字化けを愛でていこう。ランキング上位の文字から、私の独断と偏見で「形がかっこいい漢字」を厳選する。

さて、これらの漢字をどう愛でるか。考えた末にたどり着いたのはプラ板だ。





せっかくなので文字化けTシャツも作った。インターネットで1枚からオリジナルTシャツを作ってくれるサービスを使った。わざと文字化けさせた状態で発注したので、担当者さんが気を利かせて文字化け前の文字に修正しないか心配だ。

ここでちょっと一息。せっかくなので文字化けの仕組みについて説明させてほしい。出来るだけ簡単に伝えるためデフォルメしてやや不正確になっている部分もあるが、そこはご容赦いただきたい。あと、そもそも文字化けの仕組みに興味がない人はページをグっとスクロールして西村さん登場のところまでスキップしてください。
そもそも文字化けはなぜ発生するのか。それは、文字コードと呼ばれるものに秘密がある。コンピュータの世界では、あらゆるデータは0と1で表現される。当然、文字も0と1の連なりで表現する。そうすると、「0や1の連なりを文字に置き換えるルール」が必要になる。このルールが文字コードと呼ばれるものだ。ルールがこの世に1つしかなければ簡単なのだが、実際にはルールが何種類もあるからやっかいだ。


ところが、これを別の文字コードのルールで解釈するとどうなるか。

SJISはUTF-8とは別のルールなので正しく解釈することが出来ず、文字化けが発生した。このように、0と1の連なりを想定と異なる文字コードで解釈すると文字化けが発生する。例えるならば、フランス語で書かれた文章を英語だと思って無理やり読もうとしているようなものだ。
文字化けのイメージはつかめたと思うので、もう少しだけ詳しく説明させてください。苦痛なら次の章の西村さんまでスキップしてください。
UTF-8の文字コードで書かれた0と1の連なりをSJISとして解釈する際の文字化けを、もう少し詳しく説明する。ただし、これ以降の説明で0と1の連なりをいちいち書いていると目がしょぼしょぼするので、そのときは0と1の連なりを4桁ずつに区切り、4桁を0~9の数字1文字かA~Fのアルファベット1文字で表すことにする。すなわち、2進数から16進数への変換だ。

UTF-8は、世界中の文字のほとんどを網羅したUnicodeという辞書を、コンピュータが扱いやすいように変換したものである。日本語の文字をUTF-8で表す際のルールは次の通り。
たとえば、「ほ」はUnicodeでは「307B」で表される。これをUTF-8で表してみよう。
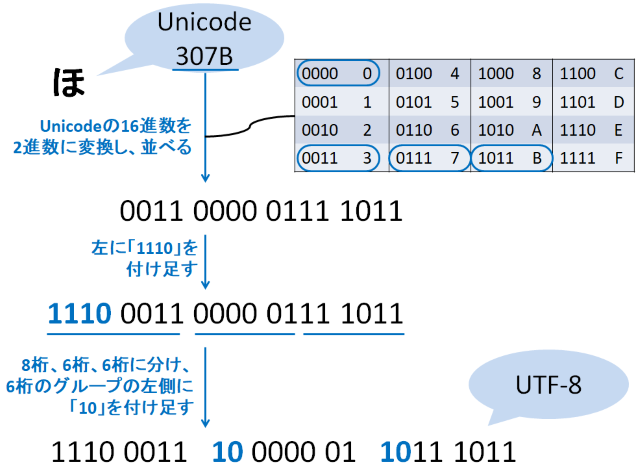
「ほ」はUTF-8では、「111000111000000110111011」と表される。目がしょぼしょぼするので、これを4桁ずつに区切って2進数を16進数に変換すると、「E381BB」となる。
コンピュータの仕組みがわかるとぞくぞくしませんか?いよいよこれをSJISで解釈してみる。文字化けの瞬間に立ち会おう。
SJISの解釈のルールはすごく簡単。(かなりデフォルメしています。)

ここで、「大きい表」というのは実際には「2バイトコード(全角文字)のエリアマップ」、」「小さい表」というのは「1バイトコード(半角文字)のエリアマップ」と呼ばれるものです。詳しくはこちらに載ってます。
これで、「ほ」がUTF-8で「E381BB」と表され、これをSJISで解釈して、「縺サ」となった。実は、変換の性質上、ひらがなやカタカナをUTF-8からSJISに変換すると、多く場合、「縺」「繧」「繝」のどれかが登場する。これが文字化けのときに糸へんの漢字がよく出る理由だ。(もっと詳しく知りたい方はこちらを読むと詳しくなれます。)
文字化けの仕組み、おわかりいただけただろうか。ちょっとでもわかった気になってもらえると嬉しいです。わかるとより愛せると思うので。
文字化けの仕組みはわかったが、文字化け後の漢字のことを私は何も知らない。「縺」「繧」「繝」。これらはれっきとした漢字であり、読み方が存在し、意味が存在するはずである。文字化け後の漢字のことをちゃんと知って、もっと文字化けと仲良くなりたい。
漢字と言えば、当サイトライターの西村さん。というわけで、西村さんに文字化け後の漢字について伺うことにした。編集部の石川さんにも撮影協力してもらった。

西村さんといえば国語辞典収集だ。国語辞典を集めるついでに漢字辞典も集まったという。将棋の羽生善治九段が趣味のチェスも強いのに似ている。ガチの人の「ついで」はつよい。
(実際には漢和辞典と漢字辞典がありますが、今回の記事では統一して漢字辞典と呼ぶことにします。)
たくさん用意してもらった中でひときわ目を引くのが、諸橋轍次(もろはしてつじ)著の大漢和辞典。下にずらっと並んでいる古そうな辞典だ。





とにかく、大漢和辞典はめちゃくちゃすごそうだ。これを使って文字化け漢字の意味を知りたい。
まずはUTF8→SJISの文字化けTOP4である、「縺」「繧」「繝」「縲」の意味を調べる。糸へん四天王だ。
どれも糸へんなので、部首から調べたいところだが、驚くべきことに「大漢和辞典」の索引巻には部首索引がない。何ということだ…。そこで、総画数を元に調べる。まずは「縺」の画数を数える。

しかし、総画数が分かったところで、同じ画数の漢字がそもそもたくさんあるので絶望的だ。そこで我々は「縺」の右側が「レン」と読めることに着目し、「レン」で音訓索引をすることにした。「レン」と読む漢字はたくさんあるが、画数の小さい順に書かれているのでいつかは見つかる。


「縺」自体は「もつれる」という意味で、「縺縷」が「寒さを防ぐ具」という意味を持つ。縺縷、気になる…。インターネットで調べても全然出てこない。
西村さん「寒さを防ぐ具ってどんなんでしょうね?上着みたいなものかなぁ。国語辞典持ってきましょうか?」
国語辞典も並べると大変な量になるので、とりあえず先に進むことにした。いつか想像で縺縷を作る、「俺たちの縺縷選手権」を開催したい。
せっかくなので他の漢字辞典でも「縺」を調べさせてもらった。


康煕字典はレベルが高すぎるので、思い切って最近の漢字辞典で調べることにした。

西村さんに別の漢字辞典でも「縺」を調べてもらった。純粋に糸のもつれでなく「話のもつれ」のように比ゆ的に使う用法は、日本だけの用法らしい。複数の漢字辞典の結果を簡単に整理する。
縺(レン)
楽しい。「縺」の意味を調べるだけで30分以上も時間がかかった。もちろん多くの話の脱線があったが…。漢字辞典は一度に多くの情報が入るので、話の脱線がどうしても多くなる。それが良いのだ。
だがこのままだと終わらないので、もう少しペースを早める。四天王の残り3つ、「繧」「繝」「縲」も調べる。


石川さん「『繧』は単体の意味がないんですね。『繧繝』でしか使わないんですかね」
西村さん「本当ですね。しかも国字と書いてあるので、『繧』は日本でしか使わない漢字のようですね。」
一方、西村さんが字源という少し昔の漢字辞典で調べたところ、「繧」が載っていない。「最近使われるようになったのかもしれませんね」とのこと。
繝(カン、ケン)
繧(ウン)
「繧繝」は糸へん四天王の2つが熟語になっているのでかなり良い。文字化け好きにはたまらない熟語だ。
縲(ルイ)
「繧繝」がおしゃれな彩色法だったのに対し、「縲」は罪人を縛る縄。糸へん四天王のギャップがすごい。
個人的に最もかっこいいと思っていた漢字が、「鐚」だ。「悪い金」だ。UTF8→EUCの文字化けでよく登場する。どんな意味なんだろう。
西村さん「悪の部分、何画か数えるのきついっすね」

西村さん、漢字辞典のアプリもたくさん持っていて、普段は紙の辞典を引かないそうだ。(こんなにあるのに!) でも今回は紙の辞典を引く楽しさも味わいたいので、アプリに助けを借りつつ、基本は紙で引く。

さて、鐚を大漢和辞典の索引でも調べる。
西村さん「11巻の634。あった、短っ!」

別の新しい漢字辞典も見てみる。もともと中国では「しころ(=兜の左右・後方に下げて首筋を覆う部分)」の意味だったようだ。「惡」は「ア」という音を表すだけで、もともと「鐚」に「悪い」という意味はなかった。しかし、日本に入ってきたときに「悪い金」と解釈して「びた銭」の意味が付いたようだ。最近になって、もともとは「しころ」だったことが分かったため、比較的新しい辞典には「しころ」が載っているが、大漢和辞典のような古い辞典には「びた銭」の意味しか載っていない。

ええー。そんな。でも、古い漢字辞典があるからこそ差分に気付けるんですね。奥が深い…。
何度も言うが、こうやって漢字をまったりと調べる時間がめちゃくちゃ楽しかった。漢字辞典は知識のかたまり。大昔の人々の言動が漢字になり、それを今、漢字辞典で眺めるという面白さ。私はここに書かれている意味の1パーセントも知らないだろう。知らないことだらけで笑えてくる。一歩進めば新しい発見がある。面白い。
鐚(ア)
次は「悤」という漢字を調べる。SJIS→UTF8の文字化けで登場する。「恩」「思」に似ているが、口のなかがごちゃごちゃしててよくわからない。
西村さん「アプリで書いても見つからないな…」
ほり「私が文字化けさせて出た「悤」をメッセンジャーで送るので、コピペして検索してください」
西村さん「来ました。あ~。ありました。分かりました。なるほど…。」
もはや文明の利器をフルに活用してたどり着いた、「悤」。「悤」は「粗忽者(そこつもの)」の「忽」の異体字で、「あわただしい」という意味。ちゃんと調べると「忽」と似た漢字で「怱」という字があって、「悤」は「怱」の親字とも出てくる。
これ、寺尾聰の「聰」の右側だ。調べると、聰は「聡」の旧字である。この文脈では「忩」が「悤」になっている。「悤」がきっかけでいろんな漢字に出会えた。
悤(ソウ)
「草が止まる止まる止まる」と書いて、「蕋」。UTF8→EUCの文字化けで登場する。調べてみると、雌蕊(おしべ)、雌蕊(めしべ)の「蕊(しべ)」の俗字ということが分かった。
西村さん「北海道に留辺蘂という町があって、それは「蕊」に木が付いたやつですね。」
蕋(ズイ、しべ)
結局2時間半ほど漢字ばかり調べていた。他にも何個か漢字を調べたが、キリがないので省略する。楽しかったなぁ。西村さんと石川さんにはお礼に文字化けキーホルダーの「鐚」と「繧」(暗闇で光るタイプ)をプレゼントした。
さて、西村さんに教えてもらった「鐚」、見た目もかっこいいが、意味もワイルドでかっこいい。もともとは防具で、日本に来た瞬間に悪銭の意味になった。びた一文は漢字で「鐚一文」である。かっこいいので、書道で表すことにした。




西村さんに文字化け漢字の意味を教えてもらったのがめちゃくちゃ楽しかった。最高の時間だった。きっかけは文字化けだったが、結局、漢字というものが面白いのだ。なんだか、文字化けを愛でるというより、漢字そのものを愛でることになってしまったなぁ。

| ▽デイリーポータルZトップへ | ||
|
記事が面白かったら、ぜひライターに感想をお送りください
> デイリーポータルZのTwitterをフォローすると、あなたのタイムラインに「役には立たないけどなんかいい情報」が届きます! →→→ Follow @dailyportalz ←←←
デイリーポータルZは、Amazonアソシエイト・プログラムに参加しています。 |
||
| ▲デイリーポータルZトップへ |

